人员分析:为什么统计不是浪费时间
文/Erik van Vulpen
许多人力资源从业者都有人力资源管理研究或工业和组织心理学的背景,而这些研究严重依赖于向学生讲授统计数据。作为一名学生,通常很难想象为什么统计数据如此重要。特别是如果你不想成为一名学术研究人员,统计数据会让你感到浪费时间。我们大多数人都希望与人合作,只是“做”人力资源,与统计数据的相关性便开始缺失。
然而,正如大多数人员分析人士所知,人力资源中统计数据的应用是我们称之为人力资源分析的基础。了解统计数据,了解如何以不同方式查看数据,以及在需要时分析数据,有助于我们做出更好的决策。
事实上,这是我经常从统计学的学生那里听到的。在制定更好和基于证据的决策方面,没有什么比对基于统计数据的结论和基本理解更有帮助了。
人员分析统计
聚合多个系统的数据并创建HR指标的仪表板,如使用Excel,Power BI或R来制作可视化数据,是实现人员分析的重要步骤。
但是,如果事实证明您拥有的数据不具代表性,那么您的结论和决定会发生什么?如果您需要轻松检查数据的质量和准确性,并轻松删除偏差结果的错误异常值,该怎么办?能够系统地思考数据对于人员分析至关重要,并且知道如何检查相关性以及因果关系成为人员分析的核心。
统计上显着的异常值
统计数据是人员分析的重要组成部分,适用于各种分析。例如:
如果您的大多数人表现“满意”,您将如何区分好或坏的表现?对数据进行区分,以得出结论并充分理解,是人员分析不可或缺的。
或者,当您启动分析项目时,您是否发现数据有回归到正常平均值的趋势?分析项目通常是对组织中问题的响应,但这个问题可能是由数据中的偶发性异常值引起的。这意味着下次我们进行测量时,这个异常值将降低到正常水平,这被称为回归均值。
另一个例子是问卷的答复率。您上次参与调查是否在组织中的不同群体之间获得了相同的回复率?或者这是你没有检查的东西?要了解某些群体在您的调查中是否过多或不足,您可以使用一些相对简单的统计技术来检查这一点。
对于我们的读者,Daniel Kahneman的书《思考的慢与快》强调了对数据进行深思熟虑和系统思考的重要性。通常我们能够在看到信息后立即快速处理信息,但这会受到我们的偏见和其他情绪的影响。只有采取更加审慎和合乎逻辑的方法,我们才能开始做出更客观的决定。统计学的学生在这方面表现得更好,因为他们知道人们容易受到的许多谬误引导。
以上为AI翻译,内容仅供参考。
原文链接:People Analytics: Why Statistics Is Not a Waste of Time
人员分析
2018年12月19日
人员分析
人员分析:在人员流动模型中建立可解释性文/Ridwan Ismeer
最近,我有幸与来自新加坡理工大学的一群才华横溢的学生一起工作。他们的任务是帮助构建一个非常普通的人员分析应用程序:预测员工流动率(此类应用程序的优点、相关性和伦理值得商榷,可以单独讨论)。
摘要:建立一个能够准确预测员工情绪的模型,在0-6个月,6-12个月和>12个月的时间范围内的周转风险。
这两项不可谈判的要求是:
1.准确性:真阳性高,假阳性低。大多数实践者会强调低假阴性,但我们有理由不这么做。
2.可解释性:在人员分析中,模型的可解释性是采用模型的关键。人员分析的最终用户通常想要理解为什么模型要预测它是什么。事实上,GDPR有新的规定要求人工智能的决定是可解释的。
现在,任何分析实践者都可以很快地指出,这两个需求之间存在一个内在的平衡。精确的模型很少是可解释的。可解释的模型很少是准确的。但我们想检验这个假设的二分法。因为在人员分析中,仅仅精确是不够的——它需要用户能够理解。
除了我们两个严格的要求外,我们还为团队提供了一个强大的人力资源指标列表、一个足够大的数据集以及评估以下算法所需的基础设施:
和往常一样,xgboost在预测营业额方面表现最好(引用Kaggle上最常用的算法之一)。事实上,它的TP和FP速率满足了我们对精度的要求。容易解释的模型,如GLM和逻辑回归只是没有比较。
然而,任何以前使用过这个算法的人都可以证明,要想弄清楚它的黑盒子里发生了什么是多么困难。我们可以告诉股东鲍勃的离职风险很高,但我们无法解释原因。
或者我们可以吗?
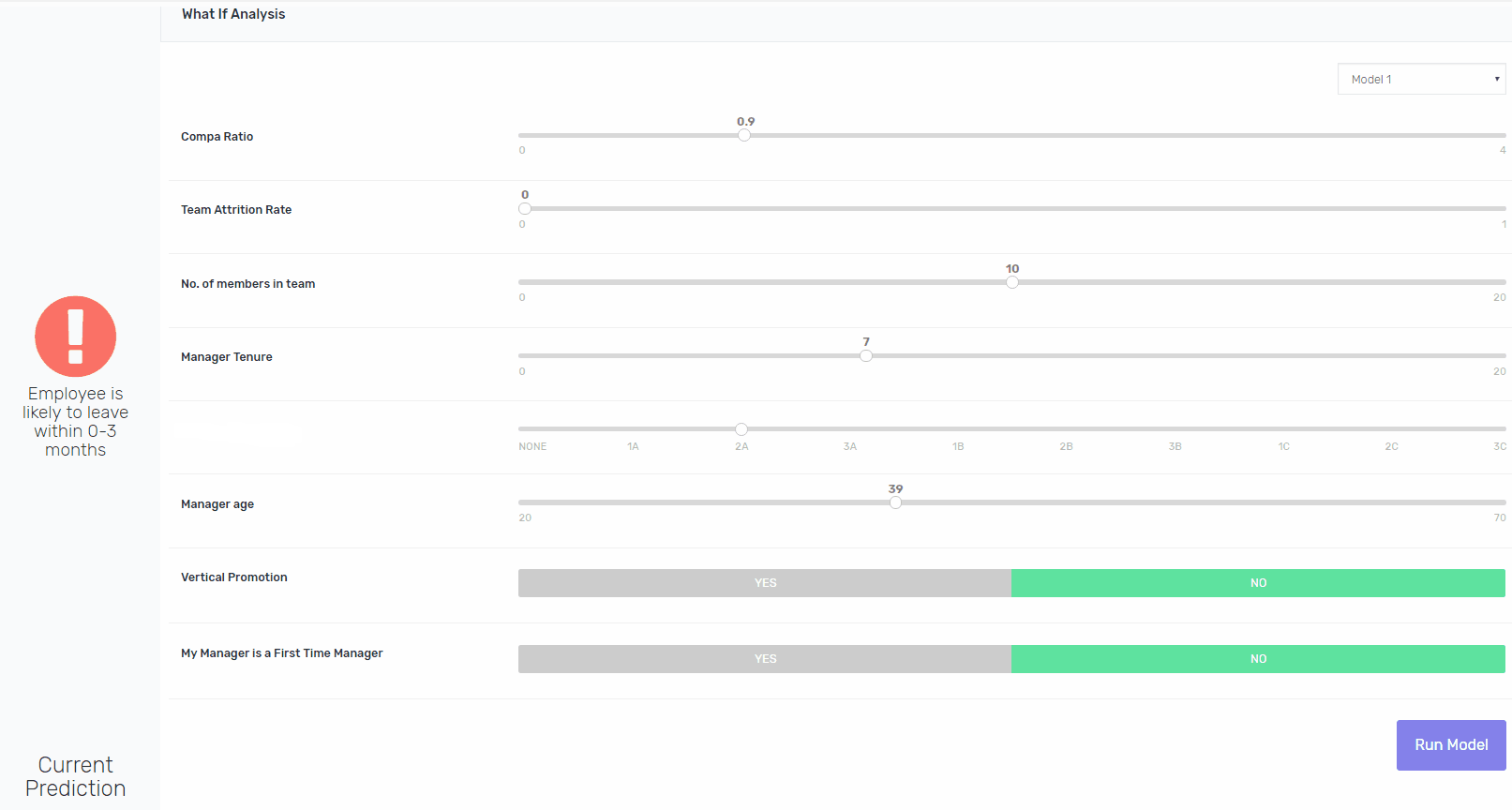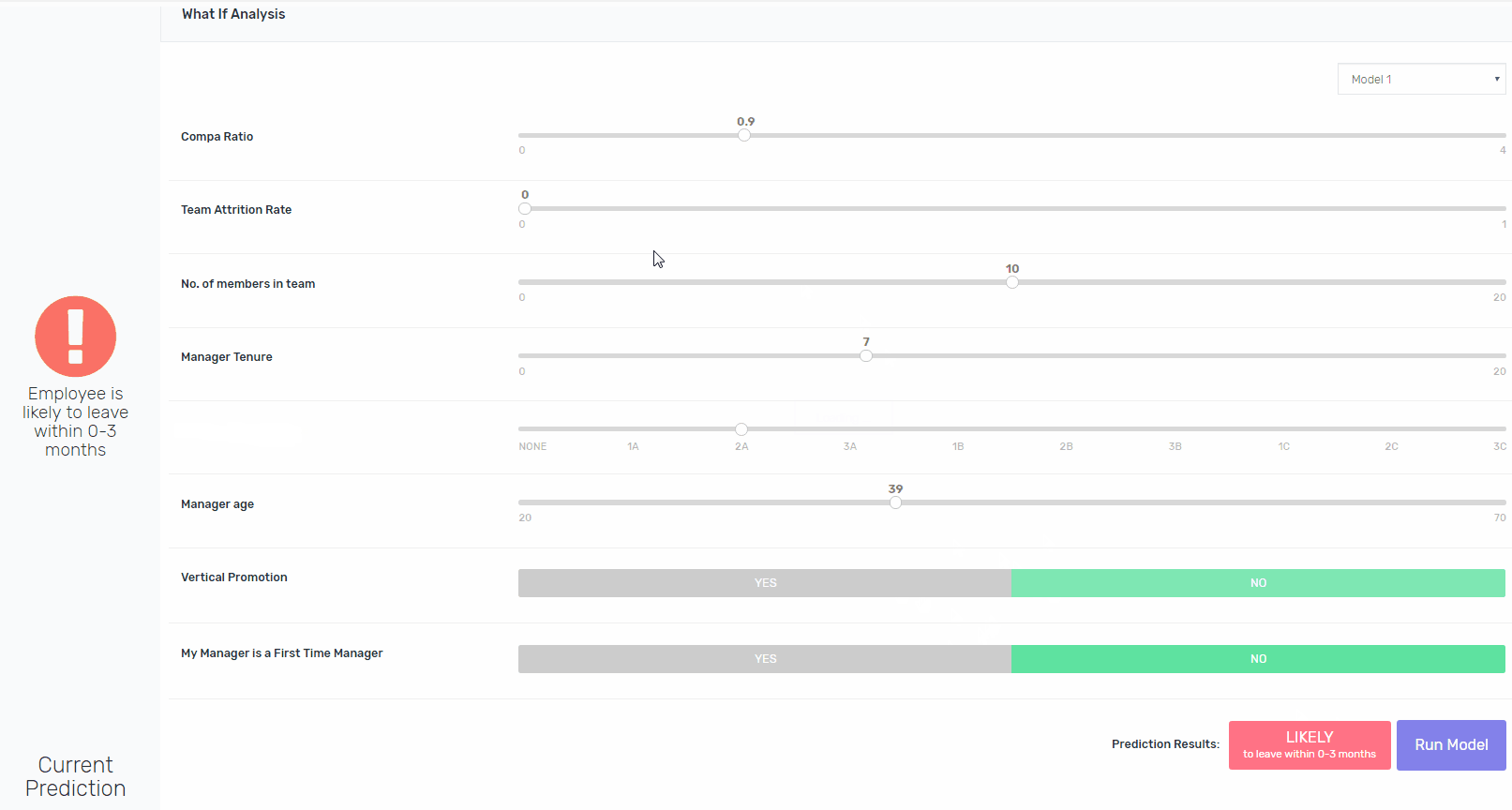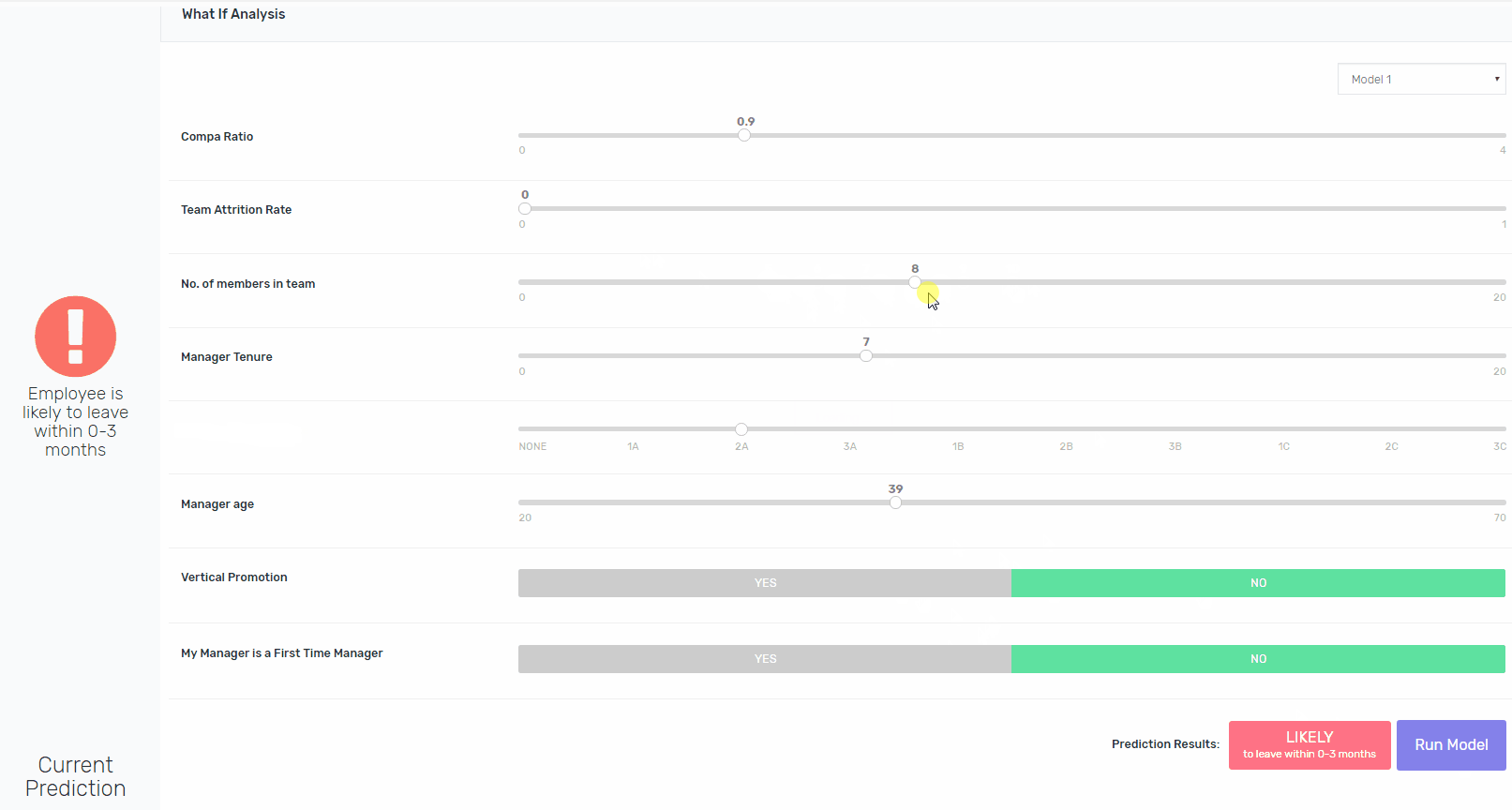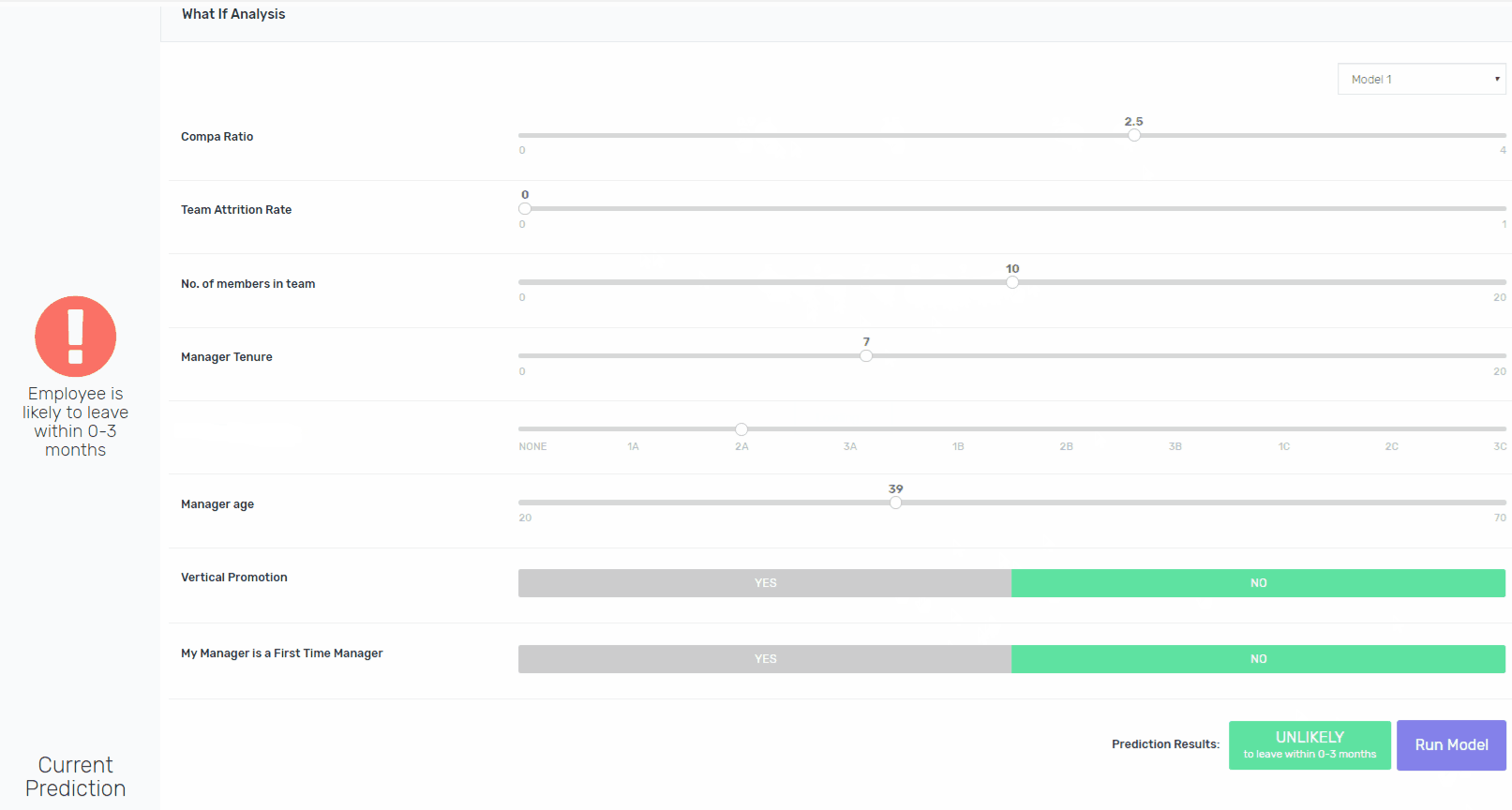
将可解释性构建到像XGBoost这样的算法中并非易事,但这是可能的。除了向涉众提供处于风险中的员工的姓名之外,我们还为他们提供了一个交互平台,用于修改现有的功能,并重新运行模型,以指向导致模型将其评为处于风险中的功能。如果鲍勃去年升职了,模特会得出同样的结论吗?是的,它将。如果Bob在一个较小的团队中,模型会得出相同的结论吗?是的,它将。如果他的工资比市场上的要高呢?不。瞧。
由于用户需要进行多次迭代才能更好地理解每个案例,因此需要进行大量的工作,但是它允许我们保持较高的准确性,同时为涉众提供必要的模型内部工作,以使其更易于解释。
一些免责声明:
1.本帖旨在解决可解释性和准确性之间的错误二分法,而不是鼓励使用个人离职模型。事实上,我甚至会说,诸如加薪和提供晋升等行动绝不应以离职风险为基础。这对精英文化来说可能是灾难性的。对一般离职动因的综合分析应该是离职模型所能做到的。
2.首先,关于可解释性的必要性有很多争论。埃尔德研究中心的约翰·埃尔德博士认为,人类过于依赖基于先前经验的确认偏差,无论如何都无法客观地解释模型的结果。辩论还在继续。点击这里了解更多内容。
3.图像中使用的数据完全是基于虚假数据,仅用于说明方法。
4.我有自己的看法。
以上为AI翻译,内容仅供参考。
原文链接:People Analytics: Building for Interpretability in Turnover Models






 扫一扫 加微信
hrtechchina
扫一扫 加微信
hrtechchina